Длительность (latency) — ключевой показатель производительности системы. На первый взгляд всё просто: рост задержки — признак деградации.
Сложность в деталях.
Представим: клиент запрашивает статический контент у веб-сервера, и мы замечаем увеличение времени ответа.
В чем может быть причина?
- Веб-сервер перегружен, запросы накапливаются в очереди.
- “Шумный сосед” забил сетевой интерфейс гипервизора.
- Соединение долго извлекается из пула — проблема локальная.
- DNS-сервер стал дольше отвечать.
Каждая операция состоит из множества этапов, и любой из них может стать узким местом.
Что делать? Улучшать наблюдаемость.
Этим и займемся :)
Постановка задачи
При анализе задержек хочется быстро и точно определять: проблема на уровне приложения или инфраструктуры?
Утилита ping кажется хорошим вариантом: измеряет Round Trip Time (RTT) между машинами, исключая уровни выше L3, тем самым предоставляя более менее “чистую” метрику состояния соединения.
Но есть недостатки:
- Работает только в реальном времени, отсутствует анализ постфактум.
- Чтобы сохранить данные для последующего анализа, придется городить дополнительные костыли вокруг ping.
- Невозможно заранее определить, какое направление сетевого трафика окажется важным.
Последний пункт можно закрыть утилитой tcpconnlat (eBPF), которая измеряет время между отправкой SYN и получением SYN-ACK.
В отличие от ping, она фиксирует задержки установки соединений для всех исходящих подключений на машине, предоставляя более полное понимание состояния сети:
# ./tcpconnlat
PID COMM IP SADDR DADDR DPORT LAT(ms)
1201 wget 4 10.153.223.157 23.23.100.231 80 1.65
1201 wget 4 10.153.223.157 23.23.100.231 443 1.60
1433 curl 4 10.153.223.157 104.20.25.153 80 0.75
Значения LAT аналогичны RTT от ping, но содержат некоторый “шум”, так как учитывают работу TCP (L4). При этом уровень приложения остается все так же за рамками.
А чтобы решить проблему исторического анализа адаптируем tcpconnlat под работу с ebpf_exporter - данные будут храниться в виде метрик.
Пишем свой первый eBPF скрипт
eBPF позволяет “перехватывать” события в ядре Linux (например, вызов функций) и выполнять пользовательскую логику: считать данные, извлекать значения аргументов или даже изменять их.
Наша цель:
- Перехватить вызов функции отправки SYN-сегмента, зафиксировать время отправки, отправителя и получателя в структуру данных (map).
- Перехватить вызов функции получения SYN-ACK-сегмента, найти соответствующую запись из пункта 1.
- Вычислить разницу между временем отправки и получения.
- Передать данные для преобразования в метрики.
Рассмотрим реализацию TCP поверх IPv4. Версию для IPv6 можно найти на GitHub.
Для начала определим функции ядра, которые будем отслеживать:
tcp_v4_connect— инициирует отправку SYN.tcp_rcv_state_process— отслеживает изменения состояния TCP-соединений, включая переходSYN-SENT -> ESTABLISHED.tcp_destroy_sock— удаляет объект сокета, после закрытия соединения. Используем её для очистки от закрытых сокетов.
Кстати, для поиска функций ядра, их аргументов и проверки гипотез удобно использовать bpftrace, но про него в другой раз.
Перехватываем события в ядре
Вот так выглядит код перехвата функций и вызов логики обработки событий:
SEC("fentry/tcp_v4_connect")
int BPF_PROG(tcp_v4_connect, struct sock *sk)
{
return trace_connect(sk);
}
SEC("fentry/tcp_rcv_state_process")
int BPF_PROG(tcp_rcv_state_process, struct sock *sk)
{
return handle_tcp_rcv_state_process(ctx, sk);
}
SEC("tracepoint/tcp/tcp_destroy_sock")
int tcp_destroy_sock(struct trace_event_raw_tcp_event_sk *ctx)
{
const struct sock *sk = ctx->skaddr;
bpf_map_delete_elem(&start, &sk);
return 0;
}
Разберем по порядку:
SEC(...)— макрос сообщает ядру, к какому событию прикрепить eBPF-программу.fentry/...— один из типов eBPF-хуков, различаются функциональностью и накладными расходами. При прочих равных лучше использоватьfentryилиtracepoint, так как у них более стабильное API и меньший оверхед.tcp_v4_connect— целевое событие в ядре.BPF_PROG— макрос, упрощающий написание eBPF-программ. Он указывает, что эта функция — eBPF-программа, и ядро должно её обработать.- В теле функции вызывается пользовательская логика, например
trace_connect().
SYN сегмент
Когда локальное приложение пытается установить TCP-соединение, ядро вызывает tcp_v4_connect(). Наш eBPF-скрипт перехватывает этот вызов и запускает код из trace_connect(sk), где sk — экземпляр структуры sock.
sock- структура ядра, представляет собой объект сетевого сокета, содержит: IP адреса, TCP порты, состояние соединения и т.д.
static int trace_connect(const struct sock *sk)
{
u32 tgid = bpf_get_current_pid_tgid() >> 32;
struct piddata piddata = {};
piddata.ts = bpf_ktime_get_ns();
piddata.tgid = tgid;
bpf_map_update_elem(&start, &sk, &piddata, 0);
return 0;
}
bpf_get_current_pid_tgid()
Этот хелпер возвращает 64-битное значение, где:- Младшие 32 бита — TID (Thread ID).
- Старшие 32 бита — TGID (или проще говоря, PID процесса).
Конструкция>> 32извлекает старшие 32 бита, чтобы получить PID.
создаем экземпляр структуры
piddata:struct piddata { u64 ts; // Таймстамп события. u32 tgid; // TGID (PID) процесса. };bpf_map_update_elem(&start, &sk, &piddata, 0);
Хелпер добавляет или обновляет элемент в карте (map)start, где ключом являетсяsk, а значением —piddata.
Map (карта) — специальная структура данных, используемая eBPF-программами для хранения и обмена данными. Она работает по принципу словаря или хэш-таблицы: имеет ключи и значения, которые можно быстро находить, добавлять или обновлять.
Определение карты start:
struct {
__uint(type, BPF_MAP_TYPE_HASH); // Тип карты: хэш-таблица.
__uint(max_entries, 4096); // Максимальное количество элементов.
__type(key, struct sock *); // Тип ключа: указатель на структуру sock.
__type(value, struct piddata); // Тип значения: структура piddata.
} start SEC(".maps"); // Имя карты.
Таким образом, при каждом вызове tcp_v4_connect() eBPF-программа сохраняет информацию о времени отправки SYN-сегмента и процессе, который инициировал соединение. Эти данные затем используются для сопоставления с полученными SYN-ACK-сегментами.
Ответный SYN-ACK
Для обработки ответного SYN-ACK ядро вызывает функцию tcp_rcv_state_process(), мы перехватываем её и запускаем handle_tcp_rcv_state_process():
static int handle_tcp_rcv_state_process(void *ctx, const struct sock *sk)
{
if (BPF_CORE_READ(sk, __sk_common.skc_state) != TCP_SYN_SENT)
return 0;
struct piddata *piddatap;
piddatap = bpf_map_lookup_elem(&start, &sk);
if (!piddatap)
return 0;
int af;
af = BPF_CORE_READ(sk, __sk_common.skc_family);
switch (af) {
case AF_INET:
return handle_ipv4(sk, piddatap);
case AF_INET6:
return handle_ipv6(sk, piddatap);
}
return 0;
}
- С помощью макроса
BPF_CORE_READчитаем поле __sk_common.skc_state - интересует только состояние SYN-SENT. - Экзепляр сокета (
sk) используется как ключ для поиска данных в картеstart. Если данные отсутствуют, выходим из функции. - Определяется тип сокета (поле
__sk_common.skc_family):AF_UNIX,AF_INET,AF_INET6,AF_NETLINK, …. - Для обработки IPv4 (
AF_INET) и IPv6 (AF_INET6) используютсяhandle_ipv4()иhandle_ipv6()соответственно.
static int handle_ipv4(const struct sock *sk, struct piddata *piddatap) {
struct ipv4_event event = {};
s64 delta;
u64 ts;
u64 delta_us;
ts = bpf_ktime_get_ns(); // Получаем текущее время
delta = (s64)(ts - piddatap->ts); // Вычисляем дельту времени
if (delta < 0)
goto cleanup;
delta_us = delta / 1000U;
// Заполняем структуру event
event.laddr = BPF_CORE_READ(sk, __sk_common.skc_rcv_saddr);
event.daddr = BPF_CORE_READ(sk, __sk_common.skc_daddr);
event.main_port = __builtin_bswap16(BPF_CORE_READ(sk, __sk_common.skc_dport));
// Строим гистограмму из карты ipv4_connection_latency_seconds
increment_exp2_histogram(&ipv4_connection_latency_seconds, event, delta_us, MAX_LATENCY_SLOT);
cleanup:
bpf_map_delete_elem(&start, &sk); // Удаляем данные из карты start
return 0;
}
increment_exp2_histogram()- это функция самого ebpf_exporter для создания метрик гистограмного типа, подробнее в документации.определение карты
ipv4_connection_latency_seconds:
struct {
__uint(type, BPF_MAP_TYPE_HASH);
__uint(max_entries, (MAX_LATENCY_SLOT + 1) * MAX_PORTS);
__type(key, struct ipv4_event);
__type(value, u64);
} ipv4_connection_latency_seconds SEC(".maps");
где ключом выступает структура ipv4_event:
struct ipv4_event {
u32 laddr; // локальный IP-адрес
u32 daddr; // удаленный IP-адрес
u16 main_port; // порт удаленной машины
u64 bucket; // бакет для гистограммы
};
А для записи длительности установки соединения подойдет беззнаковое u64.
Создание метрик
На этом этапе все данные собраны. Теперь настроим ebpf_exporter для их правильной интерпретации и определим необходимые лейблы.
Создадим еще один файл с расширением .yaml:
metrics:
histograms:
# Название карты (map) с финальными данными и описание метрики
- name: ipv4_connection_latency_seconds
help: IPv4 Connection Latency histogram
# Настройка гистограмы.
# https://github.com/cloudflare/ebpf_exporter?tab=readme-ov-file#histogram
bucket_type: exp2
bucket_min: 0
bucket_max: 26
bucket_multiplier: 0.000001
# Определение лейблов, значения которых соответствуют подрядку полей структуры `ipv4_event`.
# https://github.com/cloudflare/ebpf_exporter?tab=readme-ov-file#labels
labels:
- name: laddr
size: 4
decoders:
- name: inet_ip
- name: daddr
size: 4
decoders:
- name: inet_ip
- name: main_port
size: 8
decoders:
- name: uint
- name: bucket
size: 8
decoders:
- name: uint
Итоги
Осталось запустить ebpf_exporter, настроить в Prometheus сбор метрик и построить необходимые графики.
Например так:
histogram_quantile(0.90, rate(ebpf_exporter_ipv4_connection_latency_seconds_bucket{}[$__rate_interval]))
Теперь нам доступны метрики длительности установки соединений:
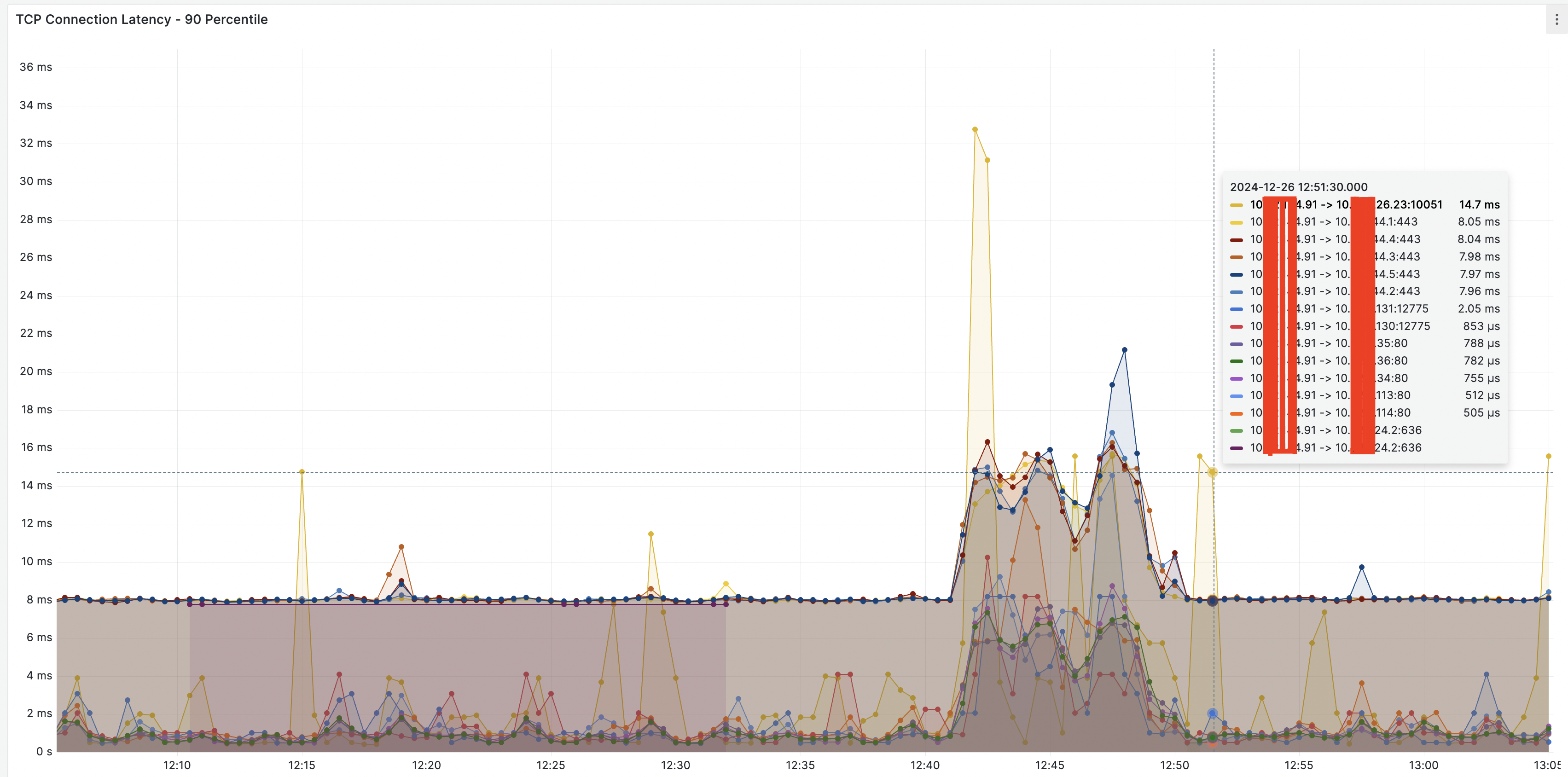
И отвечать на вопрос “в чем причина замедления: в приложении или инфраструктуре?” становится немного проще.
Полная версия исходного кода доступна на GitHub.
Удачи!